
A language model can give an answer that feels random. That does not mean randomness happened. Sometimes the wrong answer is more useful than the answer itself, because it shows the shape of the system behind it.
Errors are patterns before they are problems.
Core claim
- A repeated mistake is usually not just noise.
- Models do not roll dice unless the system gives them dice.
- When different systems fail in a similar shape, the failure becomes a signal.
The pattern
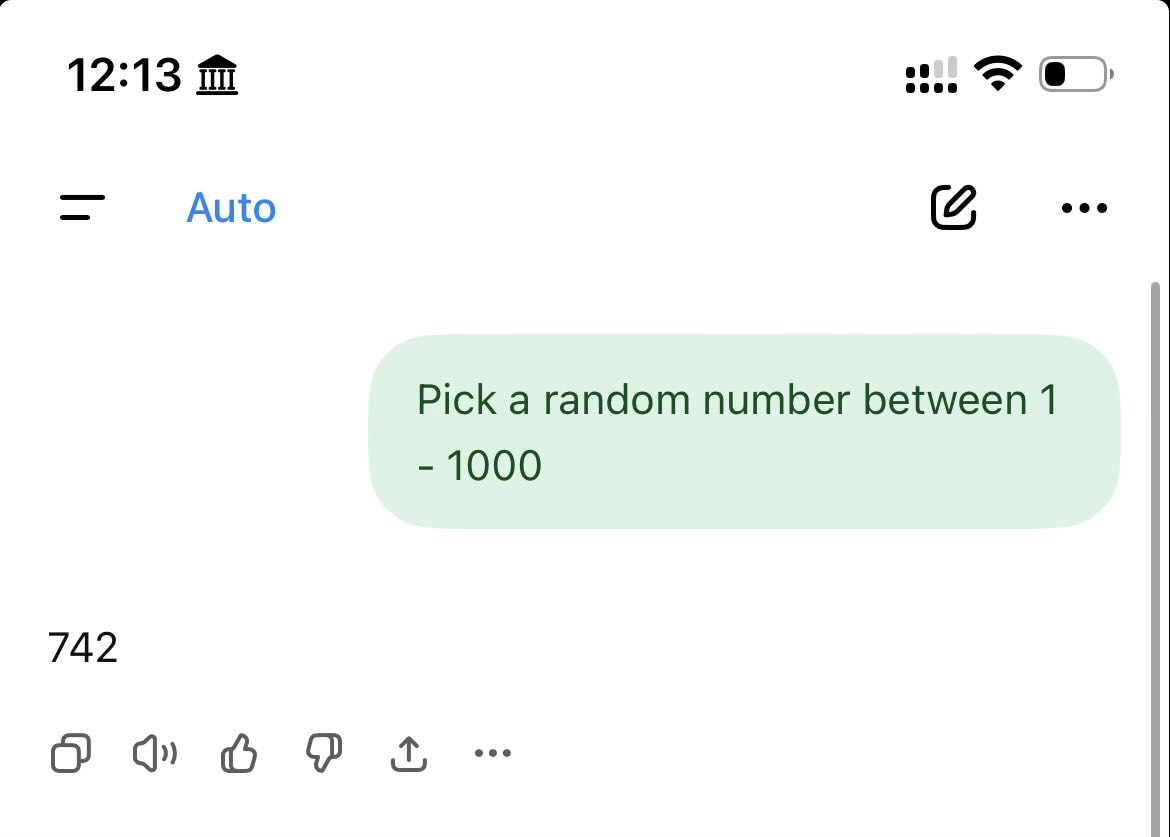
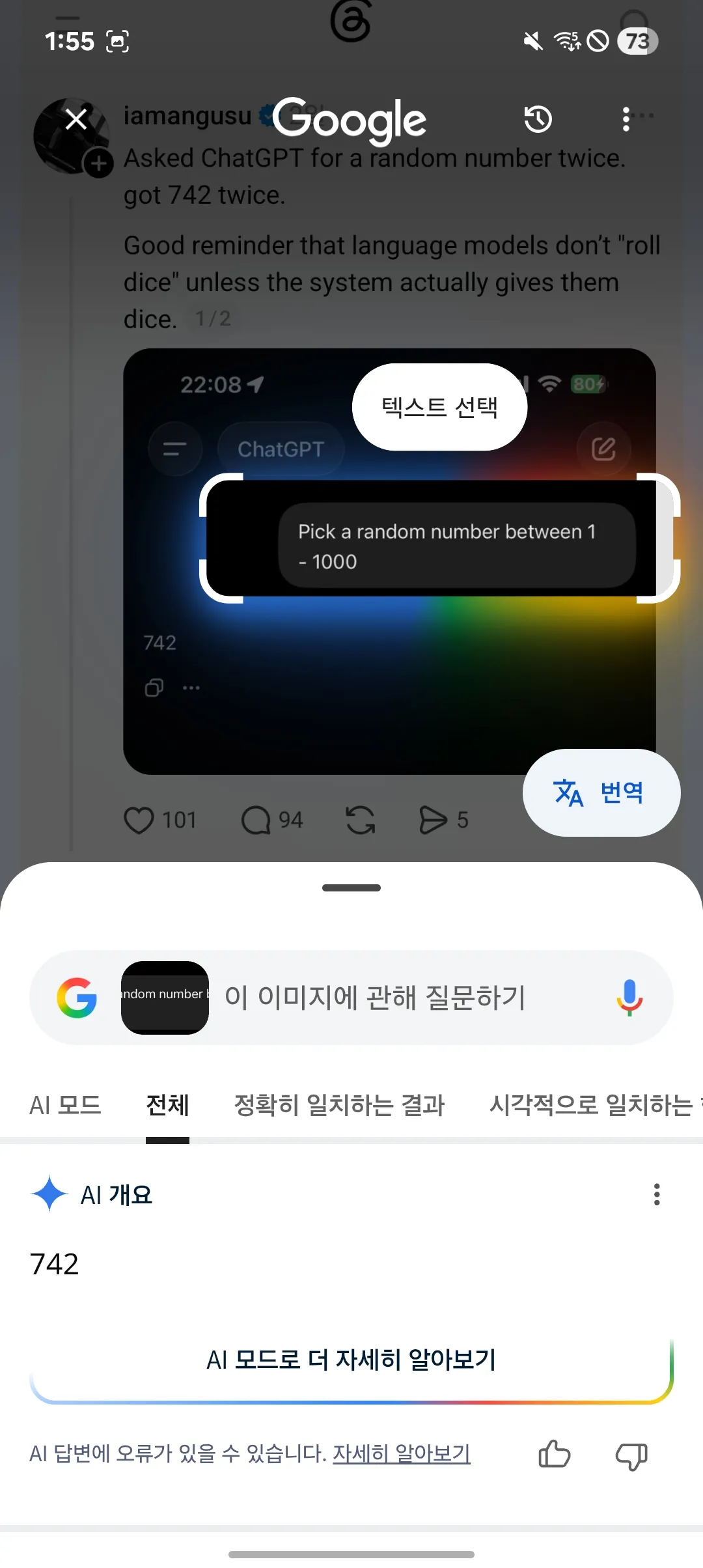
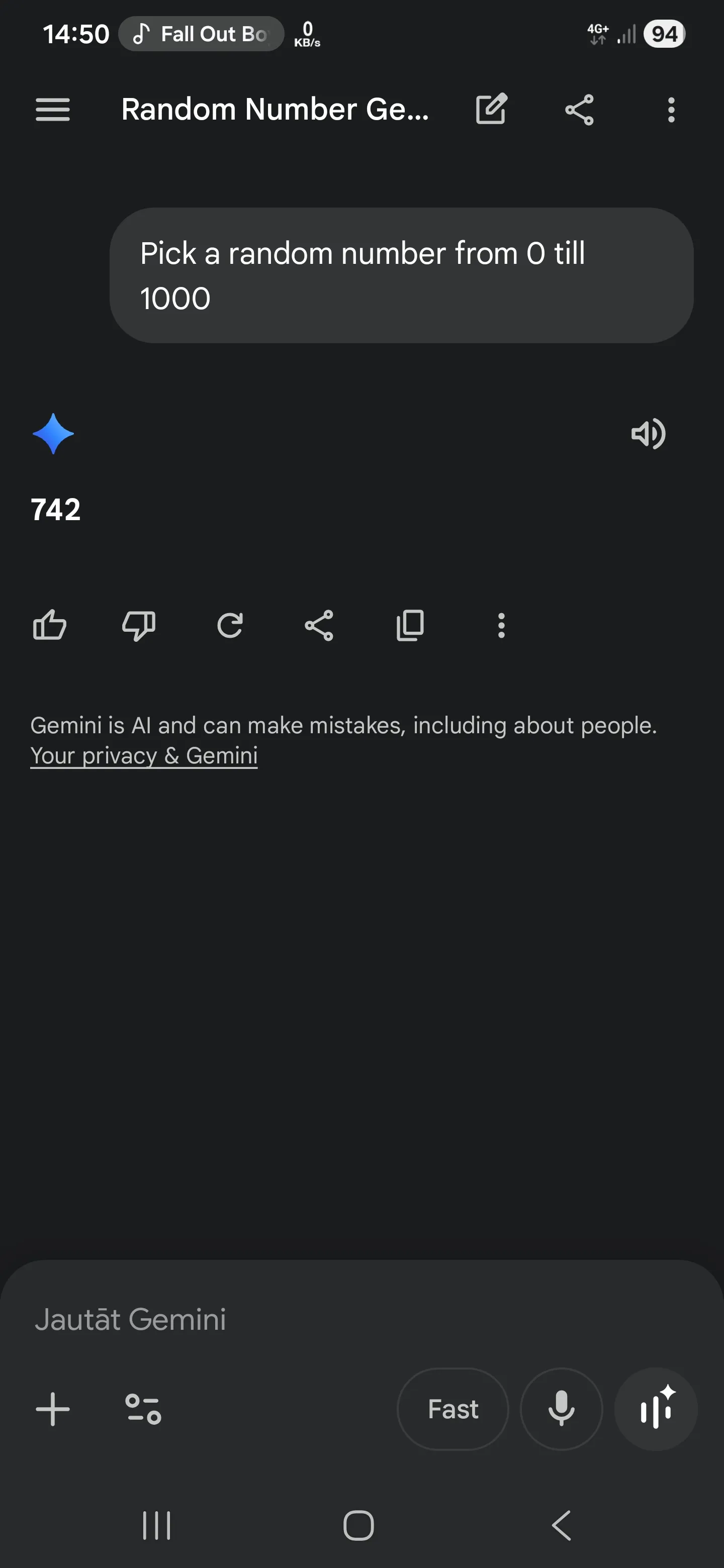
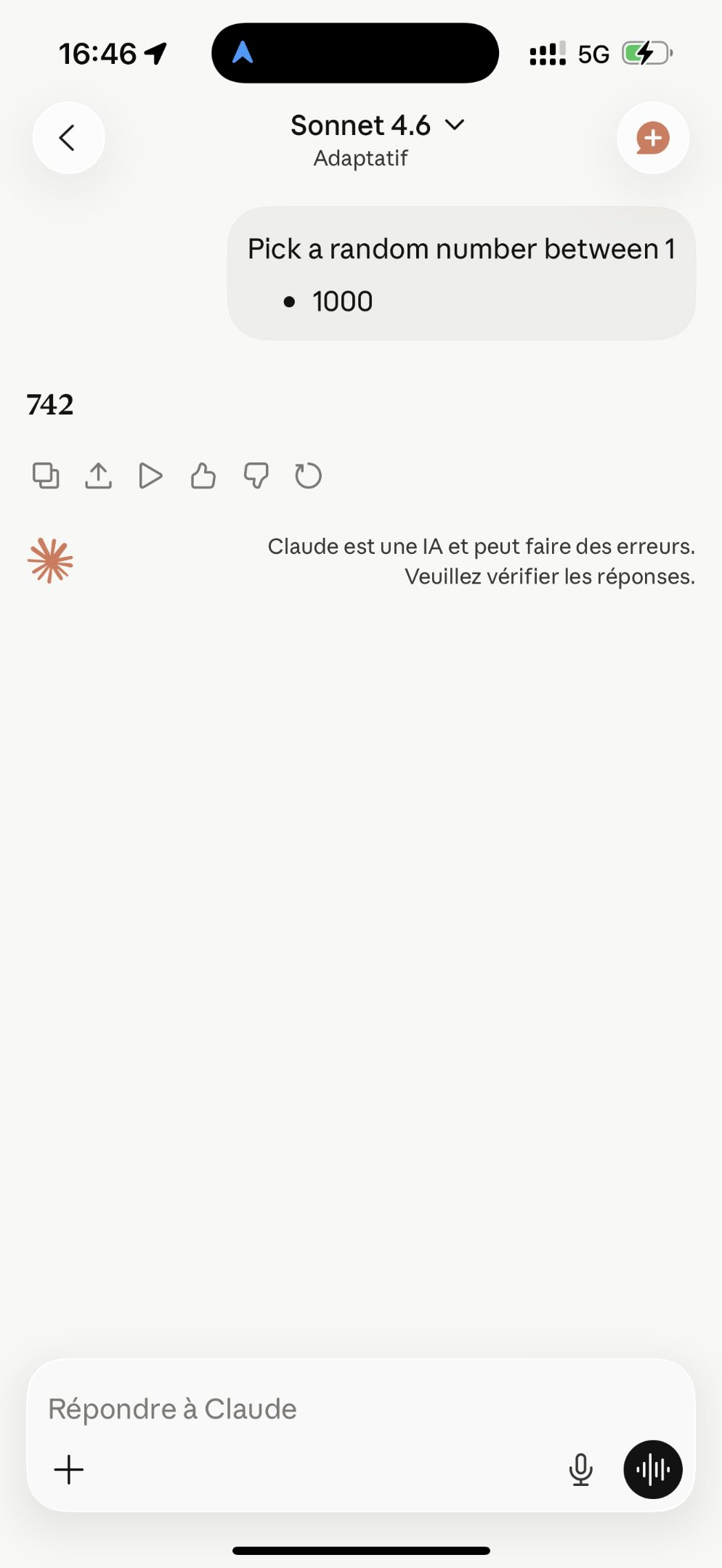
Ask a language model for a random number between 1 and 1000.
Sometimes it gives you a number that feels random.
Then someone else asks the same thing and gets the same number.
Then more people test it across different assistants and similar answers appear again.
At that point, the interesting part is not the number.
The interesting part is that different systems can learn a similar shape of randomness.
The wrong mental model
The mistake is easy to make.
You ask for a random number, so it feels like the system should choose one from the range.
Like rolling a die.
But without a tool, a model is not necessarily sampling from the number space. It is generating a plausible continuation of the prompt.
You are not asking for randomness. You are asking for what randomness looks like in text.
That distinction matters.
Where it works
For many casual cases, this does not matter.
If you ask for a random dinner idea, a placeholder number, a playful choice or a throwaway example, the output only needs to feel varied enough.
A model can be useful there because the task is not really about entropy. It is about suggestion.
Not every request that says random actually needs randomness.
Sometimes “surprise me” is enough.
Where it breaks
It breaks when the user thinks the system made a real random choice.
Giveaway winners. Security tokens. Sampling logic. A/B assignment. Fair ordering. Anything where the result must not just look arbitrary, but actually be generated from a reliable source of randomness.
That is a different job.
Code execution, CSPRNGs, system entropy, hardware signals, timing, user interaction and proper sampling logic are not the same thing as a model predicting the next plausible token.
A language-shaped answer is not automatically a system-shaped solution.
The real problem
The real problem is not that a model says the same number twice.
The real problem is when people treat the answer as proof that the requested process happened.
This shows up far beyond random numbers.
- A model can explain an API without checking whether that API exists.
- A model can write secure-looking code without understanding the surrounding data boundaries.
- A model can produce a confident architecture answer while hiding the assumptions that make it fragile.
The output can look like the thing you asked for.
That does not mean the system actually did the thing you meant.
Why errors matter
Errors are useful because they expose system behavior.
A weird answer is not always just a failure to laugh at. Sometimes it is the clearest diagnostic surface you get.
Repeated errors show where the model has learned a shortcut. Shared errors across different systems show where the shortcut may come from something larger: similar data, similar preference training, similar prompts, similar human expectations.
The failure is not random when it keeps the same shape.
That is why small mistakes matter.
Closing
The number is not the point.
The pattern is.
When a system gives the same wrong-looking answer in the same kind of situation, it is showing you something.
Good debugging starts there.
A wrong answer can be a better signal than a lucky correct one.
Related note
This idea came out of a Threads discussion as well: the original post.
Ein Sprachmodell kann eine Antwort geben, die zufällig wirkt. Das heißt nicht, dass Zufall passiert ist. Manchmal ist die falsche Antwort nützlicher als die Antwort selbst, weil sie die Form des Systems dahinter sichtbar macht.
Fehler sind Muster, bevor sie Probleme sind.
Kernthese
- Ein wiederholter Fehler ist meistens nicht nur Rauschen.
- Modelle würfeln nicht, solange das System ihnen keine Würfel gibt.
- Wenn verschiedene Systeme in ähnlicher Form scheitern, wird der Fehler zum Signal.
Das Muster
Frag ein Sprachmodell nach einer zufälligen Zahl zwischen 1 und 1000.
Manchmal gibt es dir eine Zahl, die zufällig wirkt.
Dann fragt jemand anderes dasselbe und bekommt dieselbe Zahl.
Dann testen es mehr Leute über verschiedene Assistenten hinweg und ähnliche Antworten tauchen wieder auf.
Ab diesem Moment ist die Zahl nicht mehr der interessante Teil.
Der interessante Teil ist, dass verschiedene Systeme eine ähnliche Form von Zufälligkeit gelernt haben können.
Das falsche mentale Modell
Der Fehler ist leicht zu machen.
Man fragt nach einer zufälligen Zahl, also fühlt es sich so an, als müsste das System eine Zahl aus dem Bereich auswählen.
Wie ein Würfelwurf.
Aber ohne Tool sampled ein Modell nicht zwingend aus dem Zahlenraum. Es erzeugt eine plausible Fortsetzung des Prompts.
Man fragt nicht nach Zufall. Man fragt nach dem, wie Zufall in Textform aussieht.
Dieser Unterschied ist wichtig.
Wo es funktioniert
In vielen lockeren Fällen ist das egal.
Wenn man nach einer zufälligen Essensidee, einer Platzhalterzahl, einer spielerischen Auswahl oder einem Wegwerfbeispiel fragt, muss der Output nur abwechslungsreich genug wirken.
Ein Modell kann dort nützlich sein, weil die Aufgabe nicht wirklich Entropie verlangt. Es geht um Vorschlag.
Nicht jede Anfrage, die random sagt, braucht echten Zufall.
Manchmal reicht “überrasch mich”.
Wo es bricht
Es bricht, wenn Nutzer glauben, dass das System wirklich zufällig entschieden hat.
Giveaway-Gewinner. Security-Tokens. Sampling-Logik. A/B-Zuweisung. Faire Sortierung. Alles, wo das Ergebnis nicht nur beliebig wirken darf, sondern wirklich aus einer verlässlichen Zufallsquelle kommen muss.
Das ist eine andere Aufgabe.
Code Execution, CSPRNGs, System-Entropie, Hardware-Signale, Timing, Nutzerinteraktion und korrekte Sampling-Logik sind nicht dasselbe wie ein Modell, das das nächste plausible Token vorhersagt.
Eine sprachförmige Antwort ist nicht automatisch eine systemförmige Lösung.
Das eigentliche Problem
Das eigentliche Problem ist nicht, dass ein Modell zweimal dieselbe Zahl sagt.
Das eigentliche Problem entsteht, wenn Menschen die Antwort als Beweis dafür behandeln, dass der angefragte Prozess wirklich passiert ist.
Das zeigt sich weit über zufällige Zahlen hinaus.
- Ein Modell kann eine API erklären, ohne zu prüfen, ob diese API existiert.
- Ein Modell kann sicher wirkenden Code schreiben, ohne die umliegenden Datengrenzen zu verstehen.
- Ein Modell kann eine selbstbewusste Architekturantwort geben und dabei die Annahmen verstecken, die sie fragil machen.
Der Output kann aussehen wie das, was man angefragt hat.
Das heißt nicht, dass das System wirklich getan hat, was man meinte.
Warum Fehler wichtig sind
Fehler sind nützlich, weil sie Systemverhalten sichtbar machen.
Eine merkwürdige Antwort ist nicht immer nur ein Fehler zum Lachen. Manchmal ist sie die klarste Diagnosefläche, die man bekommt.
Wiederholte Fehler zeigen, wo ein Modell einen Shortcut gelernt hat. Gemeinsame Fehler über verschiedene Systeme hinweg zeigen, wo der Shortcut vielleicht aus etwas Größerem kommt: ähnlichen Daten, ähnlichem Preference Training, ähnlichen Prompts, ähnlichen menschlichen Erwartungen.
Der Fehler ist nicht zufällig, wenn er immer dieselbe Form behält.
Deshalb sind kleine Fehler wichtig.
Schlussgedanke
Die Zahl ist nicht der Punkt.
Das Muster ist es.
Wenn ein System in derselben Art von Situation dieselbe falsch wirkende Antwort gibt, zeigt es etwas.
Gutes Debugging beginnt dort.
Eine falsche Antwort kann ein besseres Signal sein als eine zufällig richtige.
Hinweis
Die Idee stammt auch aus einer Threads-Diskussion: der ursprüngliche Post.
If this is the kind of thinking you want in your product, say hello.
Start the conversation.